
面向星际争霸:DeepMind提出多智能体强化学习新方法
文章来源:公众号 机器之心
(选自arXiv 机器之心编译 参与:路雪、李泽南)
不久前 DeepMind 强化学习团队负责人、AlphaGo 项目负责人现身 Reddit 问答,其中一个问题是‘围棋和星际争霸 2 哪个更难?潜在技术障碍是什么?’近日,DeepMind 发表论文,提出了多智能体强化学习方法,有望为星际争霸等游戏的 AI 技术的开发提供帮助。该论文也将出现在 12 月美国长滩举行的 NIPS 2017 大会上。
深度强化学习结合深度学习 [57] 和强化学习 [92, 62] 来计算决策策略 [71, 70]。传统来说,单个智能体与所处环境进行重复互动,从观察结果中学习,进而迭代地改善自己的策略。受近期深度强化学习成就的启发,DeepMind 的研究人员对多智能体强化学习(multiagent reinforcement learning,MARL)重新燃起了兴趣 [88, 16, 97]。在 MARL 中,多个智能体在一个环境中同时互动和学习,可能是围棋和扑克中的竞争模式,学习如何交流的合作模式,也可能是二者皆有。
MARL 最简单的形式是独立强化学习(independent RL,InRL),每个学习器不理会其他智能体,将所有互动作为自己(‘局部’)环境的一部分。这些局部环境是非稳态和非马尔可夫的 [55],导致在很多算法中缺乏收敛保证,除此之外,研究者还发现这些策略会与其他智能体的策略产生过拟合,从而无法实现很好的泛化效果。强化学习社区对环境过拟合的研究还很少 [100, 67],但是 DeepMind 的研究人员认为这在多智能体设置中尤其重要,该设置中一个智能体必须根据观察到的其他智能体的行为动态地作出反应。经典的技术是收集或逼近额外信息如联合值(joint value)[60, 18, 28, 54]、使用适应性学习率 [12]、调整更新频率 [47, 79],或对其他智能体的动作进行在线动态回应 [61, 49]。但是,近期研究中出现了一些特例 [21, 78],他们关注(重复)矩阵博弈(matrix game)和/或完全可观察的环境。
有多个建议能够在多智能体设置中处理部分可观测环境。当模型完全可知,且设定是与两名玩家完全对抗时,可以使用策略迭代方法,该方法基于使用专家级抽象(expert abstraction)可以进行很好扩展的遗憾最小化(regret minimization)[26, 14, 45, 46]。近日,研究者将这些方法和深度学习结合起来,创建了无限下注德州扑克专家级 AI 系统 DeepStack [72]。大量研究在通用设置下,通过扩展信念状态和来自 POMDP 的贝叶斯更新 [27],处理去中心化合作问题 [74, 77]。这些模型具备较强的表达能力,得出的算法也比较复杂。在实践中,由于难解性,研究者通常使用近似式(approximate form),通过采样或利用结构来确保模型保持优秀性能 [40, 2, 66]。
在这篇论文中,DeepMind 的研究者介绍了一种新的指标,用于量化独立学习器学得策略的关联效果,并展示了过拟合问题的严重性。这些协调问题在完全可观测的环境中已经得到充分研究 [68]:DeepMind 的研究者在部分可观测的混合合作/竞争设置中观察到了类似问题,并证明其严重性随着环境可观测的程度降低而增加。DeepMind 的研究者提出一种基于经济推理(economic reasoning)的新型算法 [80],该算法使用(i)深度强化学习来计算对策略分布的最佳回应,(ii)博弈论实证分析(empirical game-theoretic analysis)来计算新的元策略分布。研究者为去中心化执行进行中心化训练:策略以分离的神经网络的形式呈现,智能体之间没有梯度共享或架构共享。基本形式使用中心化支付矩阵(payoff table),但在需要更少空间的分布式、非中心化形式中该矩阵被移除。
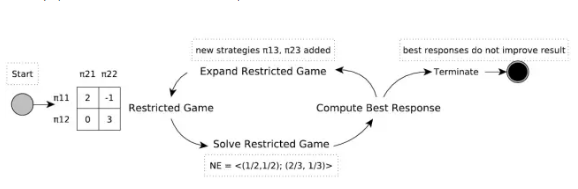
DeepMind 的研究人员展示了他们的主要概念性算法:策略空间回应 oracle(policy-space response oracles,PSRO)。该算法是 Double Oracle 算法的自然泛化,其中元博弈是策略而非动作。它还是 Fictitious Self-Play 的泛化 [38, 39]。与之前的研究不同,该算法可以插入任何元求解器以计算新的元策略。在实践中,无需任何域知识,使用参数化策略(函数逼近器,function approximator)泛化至状态空间。
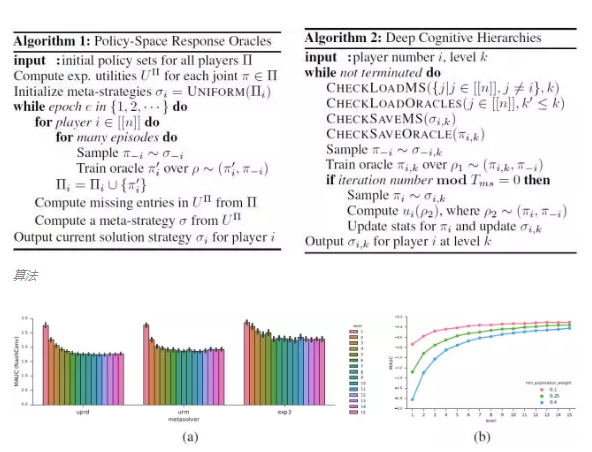
DeepMind 也展望了新方法的未来应用方向,研究人员正在考虑保持基于策略差异损失惩罚的差异性,一般响应图拓扑,实时语言游戏和 RTS 游戏等环境,以及其他需要进行预测的架构,如对立建模、在辅助任务中进行未来状态估测。DeepMind 还希望研究快速在线适应及其与计算心智理论的关系,以及对使用继任者特征的类似策略进行泛化(迁移)的 oracle。
论文:A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning

论文链接:https://arxiv.org/abs/1711.00832
要想实现通用智能,智能体必须学习如何在共享环境中与他人进行互动:这就是多智能体强化学习(multiagent reinforcement learning,MARL)遇到的挑战。最简单的形式是独立强化学习(independent reinforcement learning,InRL),每个智能体将自己的经验作为(非稳态)环境的一部分。这篇论文中,我们首先观察到,使用 InRL 学得的策略能够在训练过程中与其他智能体的策略产生过拟合,但在执行过程中无法实现充分的泛化。我们引入了一种新的指标:共策略关联(joint-policy correlation),对该效果进行量化。我们介绍了一种用于通用 MARL 的算法,该算法基于深度强化学习生成的多种策略的几乎最佳回应,还进行博弈论实证分析来计算策略选择的元策略。该算法是之前算法的泛化,如 InRL、iterated best response、double oracle 和 fictitious play(虚拟对局)。之后,我们展示了一种可扩展的实现,使用解耦元求解器(meta-solver)减少内存需求。最后,我们在两种部分可观测的设置(gridworld coordination games 和扑克)种展示了该策略的通用性。