
星际AI打不过人类? 不妨向下围棋的AlphaGo学学

文章来源:公众号 量子位
“人类总算能摆脱被统治的阴影”。
这两天,一场《星际争霸》的人机对抗“表演赛”,让不少人类感到扬眉吐气。毕竟在这场比赛中,韩国顶级职业玩家Stork(宋炳具),一鼓作气击败了四个AI玩家,赢得500万韩元奖金!
约合人民币近3万元。

整场比赛流程是这样的:人类阵营先由两个普通学生星际玩家出场,分别挑战上个月《星际争霸AI大赛》的冠军:ZZZK、来自挪威的TSCMO、主办方韩国世宗大学研发的MJ。
结果AI阵营分别以3:0、2:1击败了普通人类星际玩家,唯一的败仗由韩国星际AI贡献。总比分算是5:1。
然后就是Stork登场,以一波4:0碾压AI,挽回人类颜面。
为什么赢了四场?因为原本预计会有三场精彩的人机对决,但是Stork赢得实在是太轻松了,没办法只能临时加赛,让《星际争霸AI大赛》上排名第六的CherryPi压轴登场,结果Stork使用神族侦察机就直捣敌窟。
尽管CherryPi来自大名鼎鼎的Facebook AI研究院,但成绩真是一贯不咋地。

-
带中文解说的现场视频,可以前往这里收看:
https://www.bilibili.com/video/av15909479/
-
如果对全程感兴趣,可以科学前往这里收看:
https://www.youtube.com/watch?v=L54zoUwVPLI
不够AI的AI
顶级职业选手战胜了AI,乍一听,星际界这个情况似乎跟围棋界形成了鲜明的对照。围棋这个领域,AI战胜了顶级职业选手。
但,还真不是一回事儿。
相比之下,AlphaGo是一套复杂的人工智能系统,现在已经可以几乎不借助任何人类知识,自行学会下围棋,并且迅速的成长为高手。
关于最新版AlphaGo Zero,有人花了一张图进行解读。如果你能看懂的话,应该还蛮有意思的……

而参加这次“星际争霸人机大战”、以及上个月《星际争霸AI大赛》的人工智能系统,都在相当初级的阶段。
比如其中最厉害的ZZZK,背后是澳大利亚的程序员Chris Coxe。他独自创建了这个AI,但其中只有一些简单的学习功能,背后更多是各种预先编辑好的策略。
量子位之前也介绍过,ZZZK只能执行一种单基地Rush战术。另外,这个ZZZK能在游戏中学习一些策略,以判断哪种Rush是最有效的。
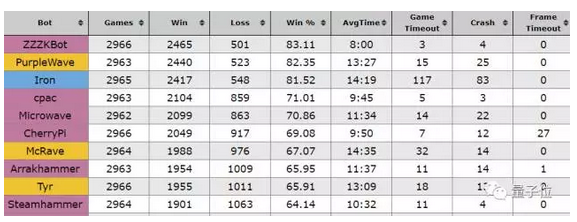
当然与普通玩家相比,星际AI还是有着人类难以比拟的优势,比方每分钟可以完成峰值2万次的操作,而人类大概是300次。
由于AI玩的不够好,就不详细解读它们的策略了。有兴趣的可以看上面提到的视频。Stork表示,跟他对局的AI出于普通玩家的中等水平。
总而言之,这次Stork击败的AI,其实不够AI。
DeepMind在干嘛
为什么AI在星际这个领域没能大杀四方?
很简单,太难了。
星际是个实用的基础AI研究环境,因为游戏本身复杂多变。AI想要取胜需要同时做多手准备,比如管理并创造资源、指挥军事单位和部署防御结构等操作需要同时进行,逐步完成。此外,AI还需预测对手的策略。
在围棋领域,Facebook开发的AI最终还是敌不过DeepMind开发的AlphaGo。而现在Facebook又在星际领域率先推出AI。
不管是有心无心,新的“竞争”开始了。不过,DeepMind在干嘛?
DeepMind当然不会错过星际;以及DeepMind选择的路径有点不一样。首先,赛场就不一样,Facebook在星际中搏杀,而DeepMind选择了星际2。其次,DeepMind没有直接推AI,而是搞了一套:SC2LE。

这是一套星际2工具包,用于加速AI研究。由DeepMind和暴雪联合发布,这个工具包中包括:
-
机器学习API:由暴雪开发,将研究人员和开发人员接入游戏,并自带首次发布的Linux工具包。至此,Windows、Mac与Linux系统均可在云端运行。
-
匿名游戏回放数据集:包含65000多场游戏记录,在接下来的几周将增加至50万场,帮助实现智能体间的离线比赛。
-
开源的DeepMindPySC2工具包:方便研究人员使用暴雪的特征层API训练智能体。
-
一系列简单的增强学习迷你游戏:帮助研究人员在特定任务上测试智能体的性能。
-
概述开发环境的论文:记录了迷你游戏的初始基线结果、监督学习数据以及智能体间完整的对抗记录。
简而言之,可以看看下面这个视频:

不止星际
AI感兴趣的游戏,不止星际一个。
DeepMind的名字深入人心,可能是因为下围棋的AlphaGo。不过,最初为这家公司在人工智能领域建立了赫赫声望的,是雅达利(Atari)的游戏。
2015年2月,也就在AlphaGo和李世乭下棋之前一年多,DeepMind第一次登上了《自然》封面,他们发表了一篇论文:Human-level control through deep reinforcement learning。这篇论文展示了DeepMind的算法如何学会了49种雅达利游戏,并在其中23种里击败人类。
比如说Video Pinball、Boxing、打砖块(Breakout)、Star Gunner、Robotank等等,AI都很擅长。

这篇论文中的算法DQN,后来成了谈到AI打游戏就一定会说起的一种算法,DeepMind和同行们都对它进行了不少改进,前不久,DeepMind还提出了一种DQN的新变体:Rainbow,论文提交给了AAAI 2018。
热衷于雅达利游戏的,还有马斯克等人联合创立的AI研究机构OpenAI。
在2016年发布的强化学习开发工具包OpenAI Gym中,集成了多个环境,其中就包含基于Arcade学习环境的雅达利游戏。
而年底发布的人工智能测试训练平台Universe更是集游戏之大成,除了2600中雅达利游戏之外,Universe里还有1000个Flash游戏。后来,Universe还引入了《侠盗猎车手5》(GTA V),让研究者用AI在虚拟世界里开车。
兴趣广泛的OpenAI,除了集成到Universe平台上的游戏之外,今年还在DotA 2圈的“世界杯”TI7邀请赛上火了一把,影魔中单solo完虐了职业选手Dendi。
可能还有《王者荣耀》。
此前多个媒体报道称,马化腾表示正在测试AI对战手游玩家。这个信息也被广泛解读为腾讯正在训练AI打《王者荣耀》。正经的说,游戏AI是腾讯一个明确的研究方向,包括LOL中未来可能也会有一个AI大魔王。
为什么科技公司不惜重金打游戏
众多科技公司,都对AI打游戏有着浓厚的兴趣,并不是一个偶然。
对于AI研究者来说,这些游戏天然为人工智能提供了一个比真实世界更简单的交互环境,又能为AI设定一个清晰的目标,同时,还提供了一个简单易用的衡量标准。
AI从游戏中学到的策略,对于现实世界中的其他领域的决策来说也有参考价值。比如说DeepMind用来打砖块的DQN,在对话系统、文本生成上就有着不错的效果,也能用来控制机器人避障、导航。
AI打GTA V,甚至本来就是为了在高仿真环境中,训练人工智能来识别街道、物体。游戏中本身就包含了大量的标注数据,比真是数据量更大、更容易获得。如果你在训练无人车的时候没有Waymo Carcraft那么高级的模拟环境,GTA也是个勉强能接受的折衷选择。
和很多打电子游戏的AI同样用了深度强化学习算法的AlphaGo,就在围棋界“独孤求败”之后找到了自己在现实世界中的价值,DeepMind说,他们期待用AlphaGo的算法,来解决蛋白质折叠、降低能耗、寻找革命性的新材料等等问题。
实际上,从2016年开始,Google就开始在数据中心里应用AlphaGo的算法,来控制风扇、空调、窗户、服务器等等的电量。谷歌说,AI帮他们提高了大约15%的能源利用效率。
打游戏的各位AI们成才之后,大可以多向这位下棋的前辈学习。